
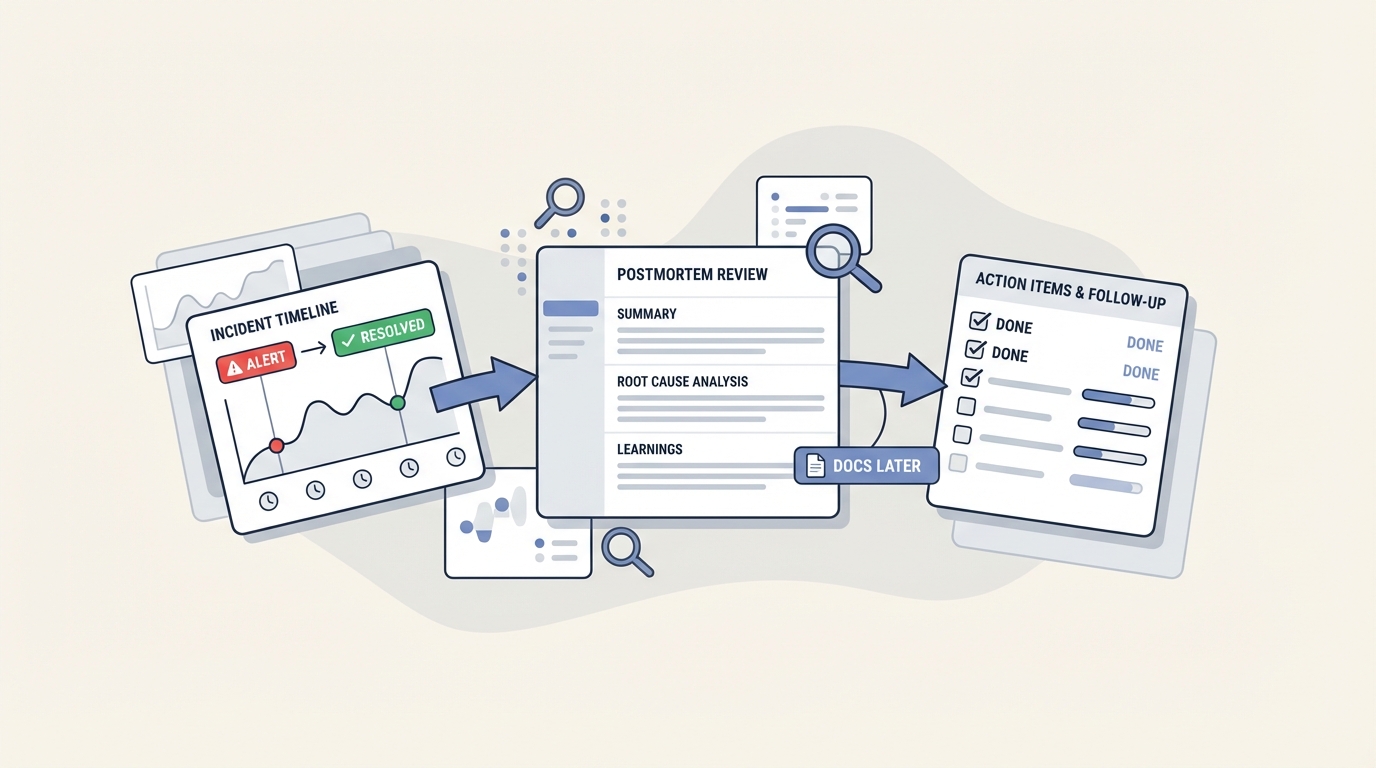
The incident is over. The fix is deployed. And now comes the question every engineering team quietly asks themselves: Do we actually have time to write this postmortem?
The answer is usually "we'll do it later." And "later" becomes "never."
This is a problem. Because the postmortem isn't paperwork—it's how you make sure this incident was the last time, not the first of many.
A good postmortem isn't about pointing fingers. As the team who wrote the book on Site Reliability Engineering at Google puts it, the goal is to fix systems and processes, not people. It's a way to turn a stressful event into a real learning moment that makes your systems stronger.
This guide will walk you through a clear, practical "docs later postmortem pattern." We'll cover how to structure the document, run the process without the blame game, and create documentation that actually leads to improvement. Writing a solid postmortem takes hours—that's why most teams don't do it consistently. But modern tools are changing things by automating the tedious parts, letting your team focus on what matters: learning.
First, let's get on the same page. A postmortem is a structured review of a production issue, whether it was a full outage or a minor hiccup. The point is to understand all the contributing factors so you can prevent a repeat performance.
The absolute key to a good postmortem is a blameless culture. This is non-negotiable. It's built on the belief that everyone acted with good intentions based on the information they had at the time. When people aren't afraid of blame, they're more likely to be open about what happened—which is the only way to find the real, systemic issues.
This is what makes a useful postmortem different from a simple incident report. A basic report might list a few facts. But as engineering leader John Allspaw notes, those reports are often "written to be filed, not to be read or learned from." A postmortem, however, is an analytical document that tells a story and is focused on learning.
Note: Some teams are moving away from the term "postmortem" (which literally means "after death") in favor of "incident review" or "learning review." The terminology matters less than the culture—call it whatever helps your team approach it with the right mindset.
Teams that skip postmortems don't just repeat incidents—they accumulate them. Each unexamined failure leaves behind invisible debt: undocumented workarounds, tribal knowledge that walks out the door, and systems that grow more fragile over time.
Consider what happens without a postmortem:
The cost of a postmortem is a few hours. The cost of not doing one is the next incident—and the one after that.
A consistent structure is your best friend for writing useful postmortems. Having a standard pattern ensures every analysis captures the right information, making it easier for anyone to learn from it, whether they were in the thick of the incident or are just reading about it six months later.

Think of this as the executive summary. Not everyone has time to read a 10-page document, so you need a top-level summary that gives them the gist in 30 seconds. It should concisely answer:
The timeline is the objective backbone of your postmortem. It's a clean, chronological log of everything that happened, from detection to resolution. This isn't the place for opinions or analysis—just the facts.
Be sure to include timestamps for everything:
Building that minute-by-minute timeline is a grind. Someone has to dig through Slack channels, monitoring dashboards, and deployment histories to piece together the sequence of events. It's tedious. It's also the foundation everything else rests on.
This manual, time-consuming task is one of the biggest reasons postmortems get delayed or skipped entirely. It feels like clerical work, and engineers would rather be writing code.
This is where tools like EkLine's Docs Agent change the game. Feed it unstructured notes, raw logs, or a Slack thread, and it drafts a structured timeline for you. What used to take hours becomes a review-and-edit job—freeing engineers to focus on analysis, not archaeology.
Here's where you connect the dots. It's tempting to find a single "root cause," like "human error," and call it a day. Don't. While techniques like the "Five Whys" can be a starting point, they can also be misleading and dangerously narrow the investigation down a single, oversimplified path.
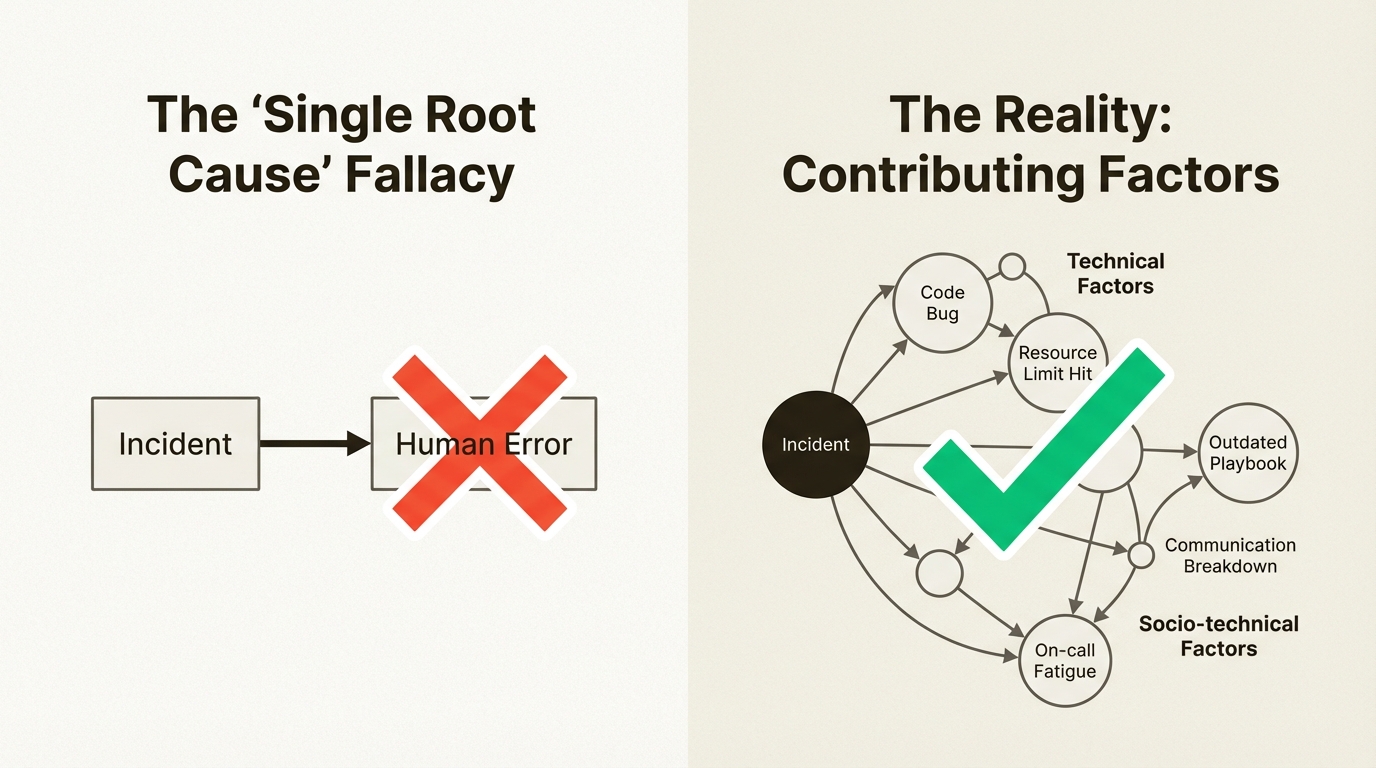
The "human error" trap
Imagine this: an engineer accidentally deleted a production database. The tempting root cause? "Human error—engineer made a mistake."
But that's not analysis. That's stopping at the first answer.
A real analysis asks:
"Human error" is almost never the root cause. It's usually the trigger that exposed deeper systemic issues. Your job is to find those issues.
Ask better questions
Instead of just asking "Why did this happen?", ask "How did it make sense for someone to do what they did at that moment?" This helps you understand the systemic context.
Your analysis should examine both:
Technical factors: A bug in the code, a misconfigured load balancer, a resource limit being hit.
Socio-technical factors: An outdated playbook, a communication breakdown between teams, an on-call engineer who was fatigued from being paged too many times.
Failures in complex systems are rarely simple. Resist the urge to oversimplify.
This is where learning turns into action. A postmortem without clear follow-up items is just a story. To make real improvements, every item needs to be specific, measurable, and assigned to someone with a due date.
Compare these two action items:
The difference is obvious. The second one is concrete and has clear ownership. Just as importantly, you need a system to track these items to completion. This closes the loop and turns a painful incident into a more resilient system.
Amid the chaos of an incident, it's easy to focus only on what broke. But documenting what worked well isn't feel-good filler—it's strategic.
Something worked during this incident. Maybe an alert fired exactly when it should have. Maybe an engineer's intuition led them to the right log file in minutes. Maybe a runbook from six months ago saved an hour of debugging. Maybe your communication to customers was clear and timely.
Document these wins for three reasons:
Understanding why things worked is just as valuable as understanding why they didn't.
Not every incident requires a 10-page postmortem. A minor hiccup with no customer impact might just need a quick note in your incident log. The goal is learning, not paperwork.
The key is consistency at each level. A SEV-3 that gets a quick note is better than a SEV-3 that gets nothing. Scale the process to the incident, but always capture something.
Having a great template is one thing, but how you get there matters just as much. The process of creating the postmortem is about guiding the team from a stressful event to a clear, valuable document.
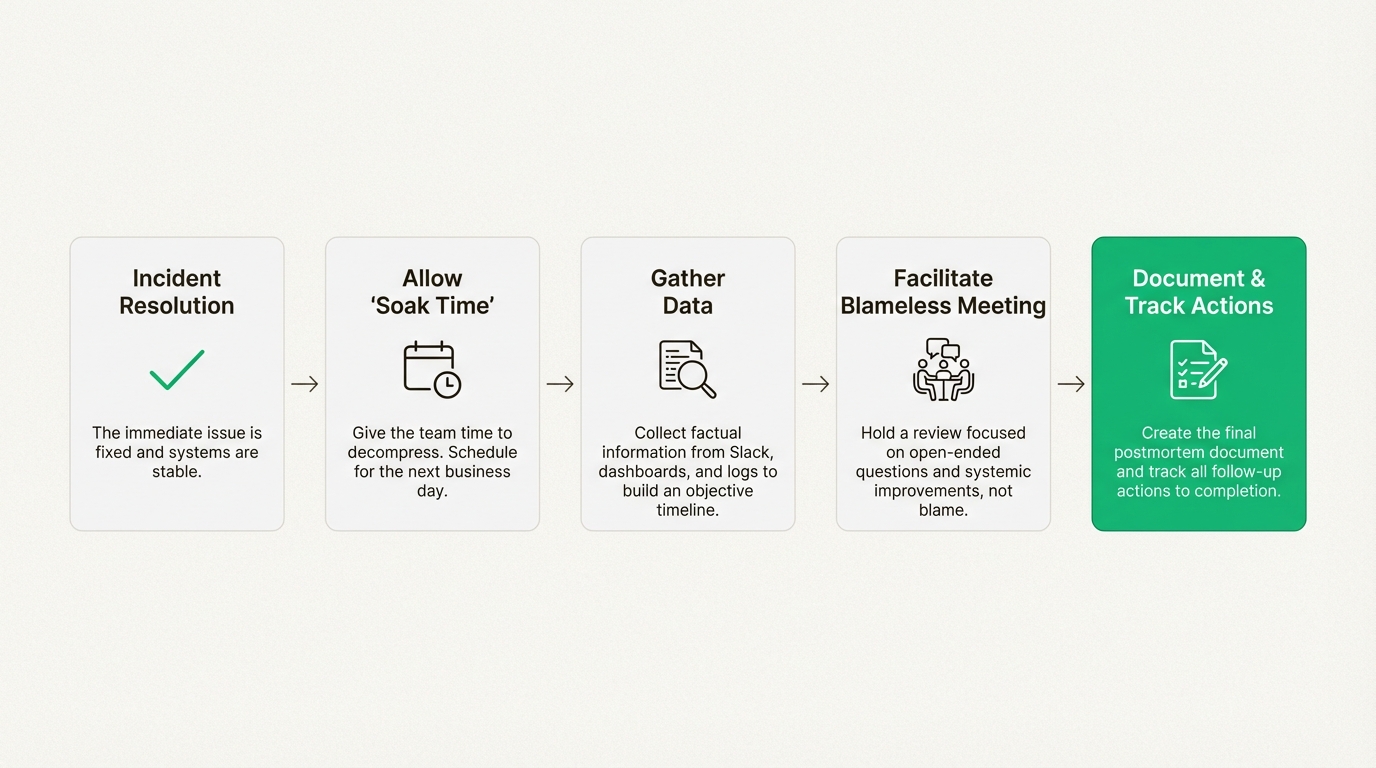
When an incident is over, the impulse is to jump straight into the review. Resist that urge. Incidents are stressful. People are tired, and their adrenaline is still pumping. Rushing into a review immediately after a stressful event is a recipe for burnout and a shallow analysis.
Give your team some "soak time." Let everyone decompress. Schedule the postmortem review meeting for the next business day. This allows emotions to settle and gives people time to switch from a reactive "firefighting" mindset to a more reflective, analytical one. You’ll get much clearer thinking as a result.
As mentioned, building that minute-by-minute timeline is a grind. It involves someone becoming a detective—sifting through Slack or Teams transcripts, checking timestamps on dashboards, and digging through deployment logs.
This friction is a major barrier to creating a consistent learning culture. When the choice is between "spend two hours compiling a timeline" and "ship the feature that's already behind schedule," the feature usually wins. The postmortem gets pushed to "later," and later never comes.
This is exactly where automation makes the difference between teams that learn and teams that repeat.
EkLine's Docs Agent is built for this. You can feed it unstructured notes, raw logs, or a Slack thread, and it drafts a structured timeline. It understands the documentation's context and style, ensuring the output is well-formatted and consistent. What used to be a two-hour archaeology project becomes a fifteen-minute review-and-edit task.
The time saved isn't just efficiency—it's the difference between postmortems that actually happen and postmortems that don't.
The review meeting is where collaborative learning happens. The goal is to build a shared understanding of the event and brainstorm effective improvements. Here are a few tips for running a great one, based on industry best practices:
1. Kick off by reinforcing the goal. Start the meeting by explicitly stating that it’s a blameless discussion focused on improving systems.
2. Walk through the timeline. Use the pre-compiled timeline to get everyone on the same page about the sequence of events.
3. Ask open-ended questions. Encourage participation by asking questions that explore context, not assign blame. Instead of "Why did you do that?" try "What information did you have at that moment?"
4. Focus on systemic improvements. Frame the conversation around, "How could our systems or processes have made this easier?" This keeps the focus on solutions.
5. Record the meeting. Not everyone involved might be able to attend. Recording the session makes the discussion accessible to everyone later.
The pattern and process are solid, but the manual effort involved is why so many teams struggle to do postmortems consistently. When you’re on a deadline, it’s easy to say, "We'll do the postmortem later," and "later" never comes. This is where AI and automation are stepping in to transform the workflow.
When multiple people contribute to a postmortem, it can quickly become a mess. One person writes in passive voice, another uses different acronyms, and the whole thing becomes hard to read. Six months later, when someone needs to reference it, they can't find what they're looking for.
Consistency matters because postmortems aren't just for the people who were in the incident—they're for the engineer who joins next year and encounters the same failure pattern.
EkLine's Docs Reviewer acts like a linter for your documentation. It automatically checks for active voice, writing patterns, and your team's specific terminology. It enforces your style guide so that every postmortem reads the same way, whether it was written by a senior SRE or a new hire.
And those links to dashboards, logs, and tickets? Over time, they break. A dashboard gets retired, a Jira project gets archived, and suddenly your postmortem is full of dead ends. Docs Reviewer includes automated broken link detection, scanning your documents to make sure they remain a reliable source of truth—not a graveyard of 404s.
Remember that tedious process of digging through logs to build the timeline? That’s a task well-suited for an AI assistant.
Tools like EkLine's Docs Agent are designed for this. You can feed it unstructured notes, raw logs, or a Slack thread, and it can help draft a structured timeline or a concise summary. It understands the documentation's context and style, which helps ensure the output is well-formatted.
This can reduce a multi-hour task to a review-and-edit job. It frees up engineers from clerical work so they can spend their time on the analysis that improves your systems.
How do you know if your postmortems are getting better? It can feel subjective—one person's "clear" is another person's "verbose."
EkLine's Quality Score removes the guesswork. It gives you a data-driven look at your documentation's health by assessing it against criteria like readability, clarity, and completeness. You can see at a glance whether a document meets your standards and get actionable insights on how to improve it.
For postmortems specifically, this helps answer questions like:
What gets measured gets improved. Quality Score makes postmortem quality measurable.
If postmortem documents are inconsistent, have broken links, or take too long to write, a team's ability to learn from them can be hindered by documentation chores.
EkLine can help automate the documentation lifecycle, from AI-powered drafting of summaries to automated quality checks. This allows teams to create consistent postmortems more efficiently, ensuring that every incident can strengthen the team and its systems.
Every skipped postmortem is a bet. A bet that this incident won't happen again. A bet that the tribal knowledge in someone's head will stick around. A bet that the next on-call engineer will magically know what this one learned.
Those bets don't pay off.
Here are the main takeaways:
The teams that build resilient systems aren't the ones that never have incidents. They're the ones that learn from every single one.
If your postmortems are inconsistent, full of broken links, or taking so long that they don't get written at all—you're not alone. Most teams struggle with this.
EkLine automates the documentation lifecycle: AI-powered drafting of timelines and summaries, automated quality checks, and broken link detection. It turns postmortems from a chore into a sustainable practice.
The result? Every incident becomes an opportunity to make your systems—and your team—stronger.
Its main goal is to turn incidents into learning opportunities. It provides a structured way to analyze what happened in a blameless manner, focusing on improving systems and processes rather than finding someone to blame.
A blameless culture encourages honesty and openness. When team members aren't afraid of being punished, they are more likely to share the crucial details needed to uncover the real, systemic issues behind an incident.
A good document should include a quick summary of the impact and duration, a detailed timeline of events, an in-depth analysis of all contributing factors (not just a single "root cause"), and a list of specific, actionable follow-up items with owners and deadlines.
"Soak time" is a recommended pause after an incident before starting the review. It allows the team to decompress from a stressful event. Rushing into a review immediately can lead to burnout and a less thorough analysis, while waiting a day often results in a more reflective and productive discussion.
Yes. AI-powered tools can automate the most tedious parts of the process, like building a timeline from chat logs or ensuring the final document follows a consistent style. This frees up engineers to focus their energy on the high-value work of analysis and problem-solving.
Each action item should be assigned to a specific owner with a clear due date. These tasks are typically tracked in a project management tool like Jira or a similar system to ensure they are completed, which closes the loop from learning to actual system improvement.
A well-structured postmortem for a SEV-1 or SEV-2 incident typically takes 2-4 hours of total effort: 1-2 hours compiling the timeline, 30-60 minutes writing the analysis, and 30-60 minutes in the review meeting. With AI-assisted tools like EkLine, you can cut the timeline compilation down to 15-30 minutes, making the whole process significantly more sustainable.




